Мы все работаем на Google! Или для чего нужна капча? - «Последние новости»
Капча стала неотъемлемой частью нашей жизни. Если вы с ней не сталкивались, вы или счастливчик, или вас просто не существует. Маленькие картинки, на которых надо отметить машины, велосипеды, светофоры и так далее, встречаются всегда и везде. Особенно часто грешит этим Google. Думаете, они нужны для того, чтобы понять не робот ли вы? Отчасти да, но есть у них и другое тайное предназначение. Надеваем шапочку из фольги и читаем дальше.

Возможно, сказанное выглядит немного странным и надуманным, но у нас с вами есть конкретные факты, которые дают понять в каком именно месте «Корпорация Добра» нас использует и конвертирует наше с вами свободное время в собственную выгоду. Лично мне это не приятно и я не хотел бы, чтобы события и дальше так развивались, но пока все именно так, а в скором времени может стать еще хуже. Ладно, давайте обо все по порядку…
Содержание
- 1 Что такое капча
- 2 Как работает капча
- 3 Что такое ИИ
- 4 Как Google пытается нас использовать
Что такое капча
Для большего понимания всего, что будет сказано ниже, рассмотрим сначала определение того, что мы привыкли называть таким словом, как «капча».
Слово это не русское и в оригинале является сокращением от нескольких английских слов. Пишется оно как CAPTCHA, а расшифровка звучит, как «Completely Automated Public Turing test to tell Computers and Humans Apart» (полностью автоматизированный публичный тест Тьюринга для различения компьютеров и людей).
ИИ бывает очень полезен: Загадочные радиосигналы из глубокого космоса поможет расшифровать искусственный интеллект
Тест Тьюринга — это эмпирический тест, идея которого была предложена Аланом Тьюрингом в статье «Вычислительные машины и разум», опубликованной в 1950 году в философском журнале Mind. Его целью было определение способности машины ввести человека в заблуждение, заставив думать, что он общается с другим человеком.

Именно этот принцип и лежит в основе алгоритма, который определяет, кто пытается отправить запрос на получение информации от сервера. Как правило, встречаются три основных типа капчи. Это плохо написанные цифрыЯ или буквы, которые не сможет определить компьютер, математические действия, которые компьютер легко выполнит, но не поймет, что их надо выполнять и определение объектов, так любимое Google.
Как работает капча
Мы остановимся именно на третьем варианте с картинками. Для того, чтобы получить доступ к информации, надо найти на картинках определенные объекты. Например, велосипеды, светофоры, витрины и так далее.
Обычная процедура, скажете вы и отчасти будете правы. Но вы когда-нибудь задумывались, почему при частично неправильном ответе, вас все равно пускают к нужной информации? Получается, никому не важно, правильно ли мы ответим? Можно объяснить это тем, что в алгоритм заложена определенная погрешность, которая допустима при прохождении этого теста. Предположим, это действительно так, но почему таким способом часто защищается простая выдача поисковика? Что такого страшного случится, если условный робот узнает сколько звезд с созвездии Ориона? Защита от DDoS-атак? Возможно, но есть и более простое объяснение.

Что такое ИИ
Компания Google, как и другие гиганты индустрии, работает над созданием своей версии искусственного интеллекта, или, как его сейчас все чаще называют, ИИ. Я немного скептически отношусь к этому словосочетанию, но оставим подобные рассуждения для другой статьи.
В современном понимании термина ИИ он представляет из себя возможность компьютера имитировать деятельность человека, в том числе, за счет машинного обучения учиться определять предметы.
Как правило, для работы таких систем их надо сначала обучить на примерах. То есть, человек показывает системе автобус и говорит, что это автобус, потом показывает костер и говорит, что это костер. Так продолжается некоторое время, после чего система сама пробует определить где что, а человек говорит права она или нет.
Вполне возможно, что система капчи от Google нацелена именно на это. Учитывая миллиарды запросов, которые пользователи по всему миру отправляют на сервер, обучение может получиться очень хорошим и полным. Даже если предложить капчу каждому десятому пользователю, все равно будет получено огромное количество данных, которые компания сможет использовать для обучения своих систем. При этом, полностью в автоматическом режиме.
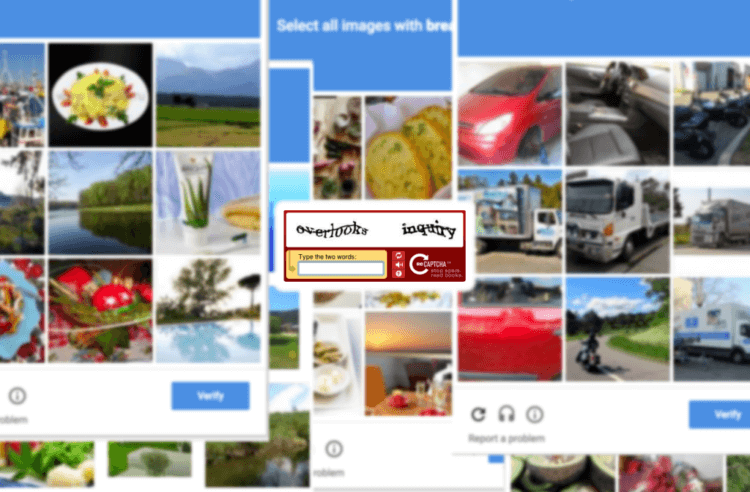
Множество вариантов капчи, с которой мы сталкиваемся каждый день
Как Google пытается нас использовать
Конечно, официально это не подтверждается, но судя по всем фактам компания именно использует нас. Подтверждением является то, что капча появляется так часто и почему-то иногда пропускает ошибки.
Если это действительно так, только представьте, сколько денег компания экономит на армии специалистов, которые должны обучать систему, распознающую изображения. Так же сказанное относится и к тем случаям, когда вам предлагается прочитать размытый текст на фасадах домов. В этой ситуации система может обучаться определять номера домов при сканировании улиц для различных картографических сервисов.

Капча с номерами домов
Например, на картинке выше приведены несколько примеров капчи с номерами домов. С одной стороны это просто не очень контрастное изображение, которое скорее всего не сможет распознать робот. С другой стороны, почему именно номера домов? Номера домов — это настоящее золото для карт от Google. Создателям сервиса не надо будет расставлять дома отдельно. Система сможет сама понять где какой номер и нанести его на карту в автоматическом режиме. А мы же потом еще и проверим полученный результат, когда не найдем нужного дома и отправим правки на рассмотрение, получив в качестве вознаграждения эфимерный статус члена команды Google. Ведь номера домов не нарисованы, а реально сфотографированы и скорее всего автомобилями Google, которые во всю колесят по дорогам, снимая улицы для «панорам».
В будущем это поможет и работе автономных автомобилей. Для подтверждения этого, стоит вспомнить картинки капчи со светофорами, пешеходными переходами и перекрестками. Именно такие картинки в не самом лучшем качестве будут выдавать камеры автопилота и системе надо будет их распознать. Пока автономных машин в широком понимании нет, но данные для них уже копятся.

Капча с поиском элементов дорожной инфраструктуры
Дополнительным свидетельством того, что это именно Google пытается накачать свои сервисы информацией являются китайские системы идентификации, которые сводятся к простой операции, вроде установки галочки в нужном месте или свайпа по экрану. У них не работает Google и им не приходится заниматься подобным сбором данных.
Пример китайской капчи
Еще один пример китайской капчи
Кроме картинок, Google предлагает распознать голосовой текст. Понимаете к чему я? У Google есть свой ассистент, которому для обучения надо с кем-то общаться и не только слушать запросы, но и понимать на сколько хорошо человек понимает то, что ему сказали. Для этого и используется система голосовой капчи.
Если это действительно так, что, Google заставляет нас работать на себя? Получается так! Только представьте, какой вклад каждый из нас вносит в большое дело обучения ИИ от Google, при этом, бесплатно. Лично меня немного напрягает после каждого запроса в Google разгадывать картинки, но я заметил, что это переходит от одного пользователя к другому. Одно время меня никто не понимал, когда я говорил, что почти каждый поисковой запрос со смартфона для меня сопровождается капчей. Потом немного отпустило, но теперь я слышу это от своих друзей и подписчиков в нашем Telegram-чате.
Получается, эпидемия капчи блуждает от пользователя к пользователю. На мой взгляд это лишний раз подтверждает теорию, приведенную выше.
Как думаете, может такое быть на самом деле? Напишите в комментариях и поучаствуйте в опросе, размещенном ниже.